python怎么读取excel文件(python读取excel文件)
在数据处理和分析领域,Python 因其丰富的库和简洁的语法而备受青睐。其中读取 Excel 文件是常见的操作,无论是处理日常办公数据还是进行复杂的数据分析,掌握 Python 读取 Excel 文件的方法都至关重要。
文章大纲:首先介绍常用的读取 Excel 文件的库;接着分别阐述各库的使用方法及示例;然后对比不同库的特点;最后总结各方法适用场景及选择建议。
Python 中读取 Excel 文件主要依赖一些强大的第三方库,其中最常用的有 pandas 和 openpyxl。Pandas 是基于 NumPy 的数据分析工具,它提供了快速、灵活且表达性强的数据结构,能轻松处理各种数据格式,包括 Excel。Openpyxl 则是一个专门用于读写 Excel 2007+(.xlsx/.xlsm/.xltx/.xltm)文件的库。
以 pandas 为例,要使用它来读取 Excel 文件,首先需要确保已经安装该库,可通过“pip install pandas”命令来安装。安装完成后,使用以下代码即可读取 Excel 文件:
import pandas as pd
读取 Excel 文件,假设文件名为 data.xlsx
df = pd.read_excel('data.xlsx')
显示读取的数据
print(df)
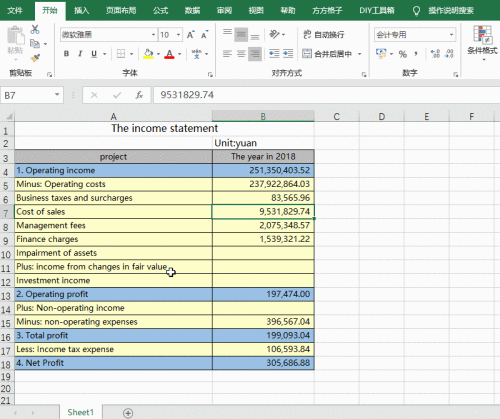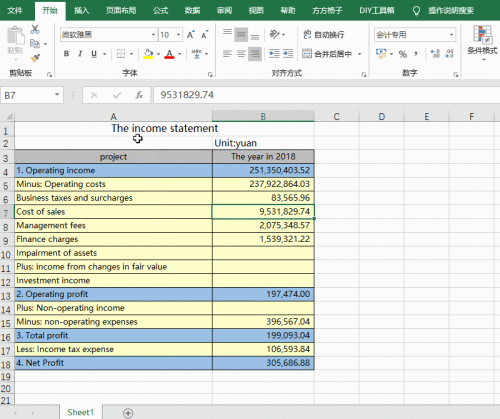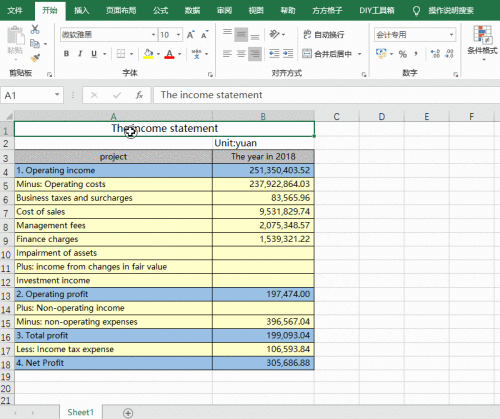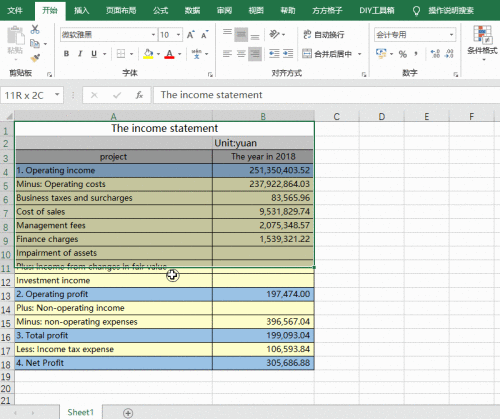
在上面的代码中,`pd.read_excel()`函数会将整个 Excel 文件读取为一个 DataFrame 对象,方便后续进行数据处理和分析。例如,如果 data.xlsx 文件中包含一张名为“Sheet1”的工作表,且工作表中有两列数据,分别是“姓名”和“年龄”,那么执行上述代码后,`df`就会包含这些数据,可以通过`df['姓名']`和`df['年龄']`来分别访问这两列数据。而且,如果在 Excel 文件中存在多个工作表,还可以通过`sheet_name`参数指定要读取的工作表,如`pd.read_excel('data.xlsx', sheet_name='Sheet2')`。
对于 openpyxl 库,其读取 Excel 文件的操作相对更侧重于对单元格的操作。同样先安装该库,使用“pip install openpyxl”命令。以下是一个简单的读取示例:
from openpyxl import load_workbook
加载 Excel 文件
wb = load_workbook('data.xlsx')
选择工作表
ws = wb['Sheet1']
读取特定单元格的值
cell_value = ws['A1'].value
print(cell_value)
遍历工作表所有单元格
for row in ws.iter_rows():
for cell in row:
print(cell.value)
在这个例子中,`load_workbook()`函数用于加载 Excel 文件,返回一个工作簿对象`wb`。通过指定工作表名称(这里是'Sheet1'),可以获取对应的工作表对象`ws`。然后可以使用方括号索引来访问特定单元格,如`ws['A1']`表示第一行第一列的单元格。通过迭代行和列,可以逐个读取并处理工作表中的所有单元格数据。不过需要注意的是,openpyxl 读取的数据类型默认都是字符串,如果需要其他数据类型,可能需要进行额外的类型转换处理。
对比两个库,pandas 更适合进行大规模的数据处理和分析,它能方便地进行数据清洗、筛选、聚合等操作,并且提供了丰富的统计分析函数。而 openpyxl 则在处理 Excel 文件的一些细节方面,如单元格样式设置、公式计算等更为擅长。
在实际的 Python 编程中,选择哪种方式来读取 Excel 文件取决于具体的应用场景和需求。如果只是简单地读取和处理数据,尤其是进行数据分析相关操作,pandas 通常是更好的选择;如果需要对 Excel 文件的格式和内容进行精细的控制和修改,如动态生成带有特定格式的 Excel 报告,openpyxl 可能更适合。熟练掌握这些库的使用,能够大大提高数据处理的效率和灵活性。
本文系作者个人观点,不代表本站立场,转载请注明出处!