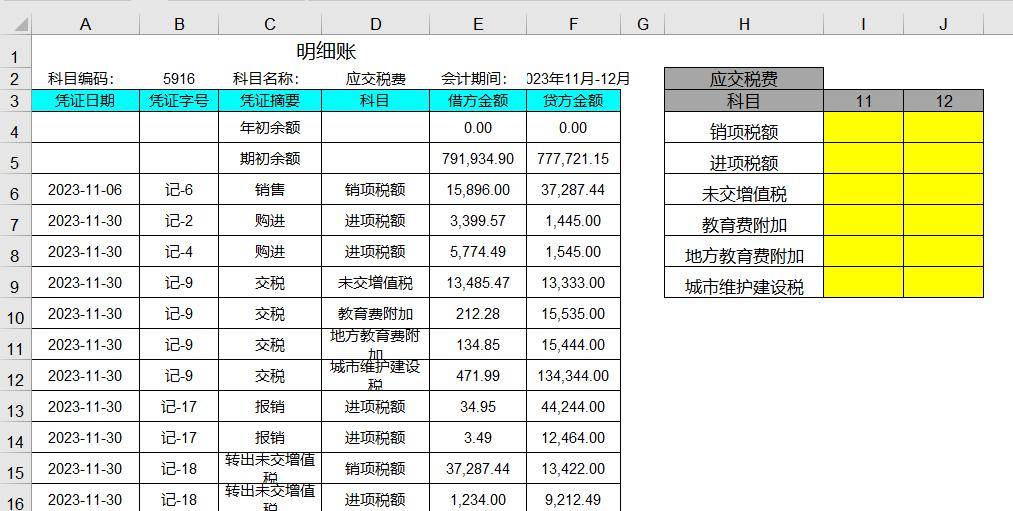
怎么把pdf转成excel表格(PDF转Excel表格方法)
在数字化的浪潮中,文件格式的转换变得尤为重要。从PDF到Excel,这一过程不仅需要技术的支持,还需要我们掌握一些基础的操作技巧。本文将详细介绍如何将PDF转换成Excel表格,包括操作步骤、注意事项以及可能遇到的问题及其解决方法。
我们需要明确转换的目标:将PDF文件中的数据提取出来,并成功导入到Excel中。这个过程大致可以分为两个步骤:第一步是将PDF文件中的内容提取出来,第二步是将提取出来的数据转换为Excel表格格式。我们将详细探讨这两个步骤的具体操作方法。
第一步:提取PDF内容
要实现这个目标,我们需要用到OCR(光学字符识别)技术。OCR是一种将图像中的文本信息转化为可编辑文本的技术。在Python中,我们可以使用`pytesseract`库来实现OCR功能。具体操作如下:
1.安装所需库:
pip install pytesseract
2.使用pytesseract读取PDF文件:
from PIL import Image
import pytesseract
image = Image.open('path_to_your_pdf')
text = pytesseract.image_to_string(image, lang='eng', config='--psm 6')
print(text)
其中 `'path_to_your_pdf'` 需要替换为你的PDF文件的实际路径。
3.提取PDF中的文本信息:
data = text.split('n')[1:-1] 获取除第一行外的所有行,并去掉最后一行
xlsx = open('output.csv', 'w')
for line in data:
xlsx.write(line + ',') 写入CSV文件,每一行以逗号分隔
xlsx.close()
这段代码会将PDF中的文本信息提取出来,并保存为一个CSV文件(即excel表格)。
第二步:转换数据为Excel表格
接下来我们需要将提取出来的文本信息转换为Excel表格。这可以通过pandas库来实现。具体操作如下:
1.安装pandas和openpyxl库:
pip install pandas openpyxl
2.使用pandas读取CSV文件:
import pandas as pd
data = pd.read_csv('output.csv')
其中 `'output.csv'` 需要替换为你刚才提取出的CSV文件的实际路径。
3.将DataFrame转换为Excel文件:
data.to_excel('output.xlsx', index=False) 写入Excel文件,index参数设置为False,表示不写入索引列
这段代码会将DataFrame对象转换为Excel文件(即excel表格)。
总结:
总的来说,通过上述步骤,我们就能将PDF文件中的内容成功提取出来,并转换为Excel表格。需要注意的是,由于PDF文件中的文本可能包含换行符、特殊符号等非标准字符,所以在转换过程中可能需要进行一些预处理工作。此外,对于复杂的表格或图片,可能需要使用更专业的OCR工具或软件来提高识别准确率。
文章大纲:
- 引言:阐述把PDF转成Excel的需求和重要性。
- 介绍OCR技术,并简要说明如何使用pytesseract库进行OCR操作。
- 讲述提取PDF内容的过程,包括使用PIL和pytesseract的方法。
- 解释如何将提取出的文本信息转换为CSV文件。
- 介绍如何使用pandas库将CSV文件转换为Excel文件。
- 强调在使用这些工具时需要注意的问题及解决方案。
本文系作者个人观点,不代表本站立场,转载请注明出处!